动机(Motivation)
对于Spark用户来说,只关心自己的业务逻辑,数据由输入到输出的pipeline,并不关注Spark应用任务执行情况和应用资源占用情况等信息。所以在提交和执行应用过程中,经常会遇到一些问题并向管理员询问,例如:
Q: 我的应用为什么运行时间超长?
A: 与应用相关的可能的原因有,业务逻辑设计不合理、算法需要优化、Executor GC时间太长、输入数据/计算倾斜,计算节点/网络存在问题,等等。。
Q: 我的应用为什么报错?
A: 需要保存应用出错信息,并且根据出错信息来进行错误排查,并反馈给用户。其中出错信息可能涉及到程序本身的逻辑和配置问题,也可能由Spark的bug、操作系统和硬件原因等触发。
Q: 为什么我的应用排队严重?
A: 与应用相关的可能原因有,应用资源占用严重不合理、内存利用率太低、Executor大量空闲、每个Executor slot任务活跃数量少等。
而Admin也会关心每个应用的执行效率,资源占用情况,应用出错信息(可能涉及到框架和集群问题,Case详见Case1)。这都需要对应用进行诊断,并给出诊断报告,作为应用排查问题和优化的依据。进一步,并且根据应用的诊断情况生成报表,按照应用出错原因、资源使用维度进行汇总形成宏观数据,以此为依据进行框架优化和资源优化。
综上,我们需要这样一个系统:
- 帮助用户和管理员,以应用为粒度,主动诊断每一个应用,并发现问题。
- 根据具体问题,给给用户建议,帮助用户自己进行程序错误修复,和资源和执行效率优化。
- 给每个应用进行标记,以便Admin定期汇总,产出Spark应用执行成功率、失败原因分类、资源占用率等报表。
这个系统包含两部分:
- Spark诊断调优模型:其中包含应用代码和配置、应用运行时和应用资源管理三个层次。
- 系统实现:其中包含实现架构,指标收集实现等。
模型(Model)
按照Spark应用从1)用户代码实现和配置设定,2)到向集群提交应用,3)应用向资源管理系统申请资源,4)开始运行这个流程,我们将诊断调优模型分为以下三个层次,如图1所示。
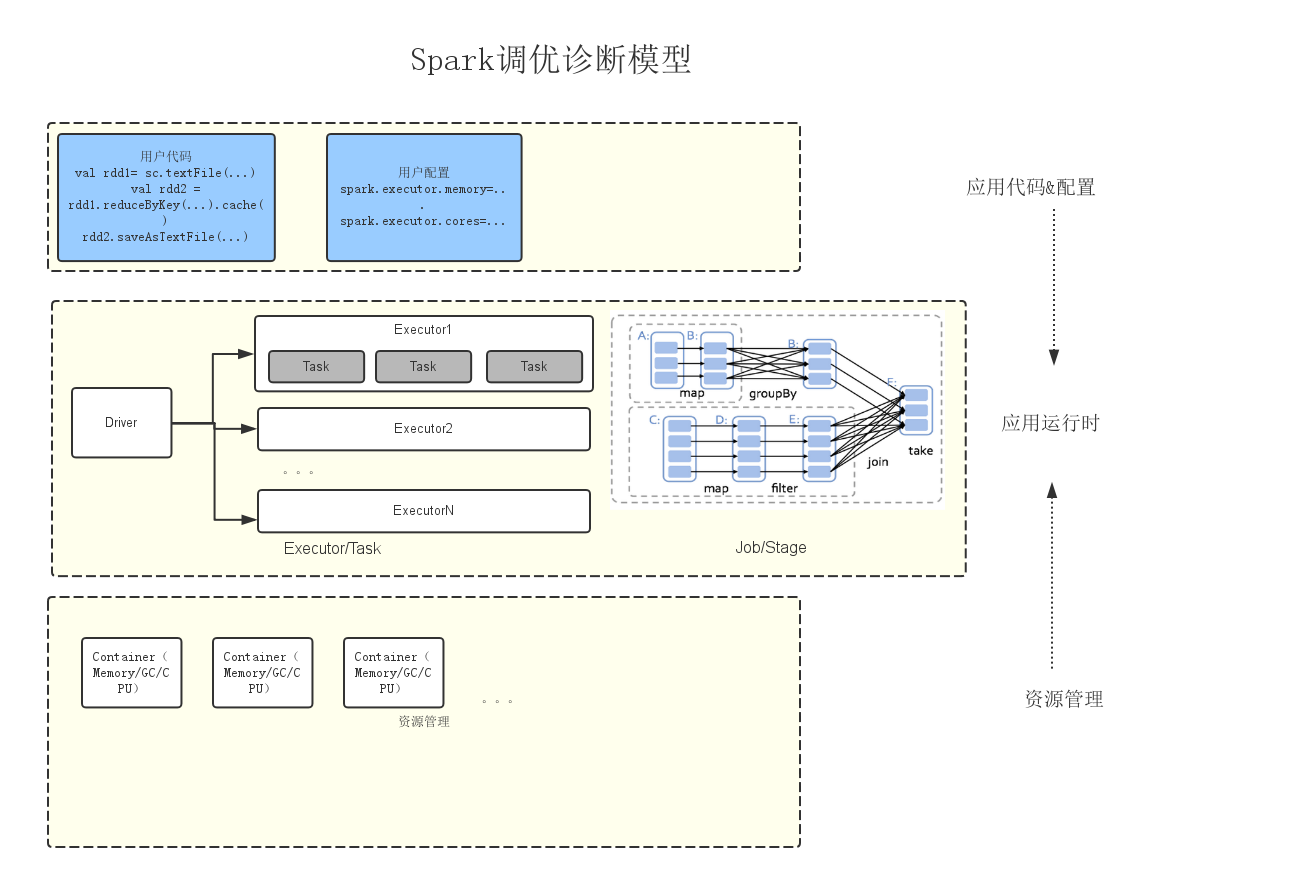
Model包含以下几个层次:
- 静态配置
- 应用运行时(三个部分)
- 资源使用(一个部分)
- 应用语义
对于每一层次内的优化项,包含指标、规则和优化建议三个内容。
静态配置
分为两类参数:一类是用户经常变动的重要参数;一类是用户不经常变动,由管理员经过优化的默认参数。
给出一些重要的参数,根据优化规则,提示用户是否在合理范围内,其次在报错的时候根据设置值来查找原因。
- spark.yarn.executor.overhead/overheadFraction:
规则,默认2g/0.2,不建议超过4g,除了特殊原因 - executor.cores:
规则:默认6,不建议超过8个,因为存在HDFS client性能问题,HDFS I/O吞吐量有瓶颈;不建议小于两个,因为slot太小的Executor不能利用到task多线程的优势。 - executor.memory:
规则:默认10g,不建议大于14g,加上overhead(2g)会提交失败; - minExecutorNum:默认1
规则:不建议大于100,除了特殊原因 - maxExecutorNum:默认100
规则:不建议大于500,除了特殊原因 - kyro的buffer:
规则:暂无,展示以为了在错误时候判断原因 - akkaFrameSize:
规则:暂无,展示以为了在错误时候判断原因
应用运行时
主要包含应用运行时的Executor和Task运行时间,各个操作时间占比相关指标,以及Job/Stage相关指标。
数据倾斜
目标:给出应用的数据倾斜程度,提醒用户存在数据倾斜,给出优化建议。
思路:抓取任务的执行时间分布、处理数据量分布等指标,根据规则判断是否数据倾斜的严重程序。
1)Task处理数据量/执行时间,平均,最大,最小,概率分布(25%、50%、75%)。
2)是否存在拖后腿任务。查看是否某些Task执行时间相对于其他差距较大。
3)Task Locality分布。
优化建议:
- 设置推测执行,spark.speculation。
- 设置合理的资源并行度,spark.executor.cores
- 设置合理的任务并行度,spark.default.parallelism
任务并行度是非常重要的参数,未来的优化方向应该是不需要用户自己进行设定,可以根据数据量等运行时数据进行自动的设定(SparkSQL已经实现一个初步版本,可以继续优化) - 业务算法改造,分布key改造。
运行时应用错误分析
目标:给予用户执行失败修改建议,让管理员可以检测到应用错误分类等信息。
思路:抓取任务失败的信息,进行归类,汇总,分析。展示信息,并且根据错误信息分类给予用户修改建议。
TaskFailed/StageFailed/JobFailed
调优建议:整理wiki,根据具体的错误原因给出修改建议。
错误总结和分类:
- Executor lost错误。可能原因有内存超出,环境配置问题等。
- 。。。
Shuffle(模型较复杂,需要继续完善)
目标:构建出Shuffle操作的耗时模型,给予用户shuffle优化建议。
思路:包含shuffle网络传输、merge排序、和spill等时间等指标,根据shuffle时间占比,来评判是否需要优化shuffle过程。
指标:
- shuffle 网络和磁盘IO时间
- shuffle 序列化时间
- shuffle 读取和spill写数据量。
shuffle 内存消耗量。
调优建议:给出优化shuffle的哪些参数,和其他优化方式:- spark.shuffle.file.buffer
- spark.reducer.maxSizeInFlight
- spark.shuffle.io.maxRetries
- spark.shuffle.io.retryWait
- spark.shuffle.memoryFraction
- spark.shuffle.manager
- spark.shuffle.sort.bypassMergeThreshold
- spark.shuffle.consolidateFiles
应用资源
目标:帮助用户自己来优化应用对于集群的CPU和内存占用,帮助管理员来掌握Spark整体的资源实际占用率情况。
思路:收集下列指标,按照对应的规则给出给出严重级别。
指标:
- Executor内存实际使用率。
- Executor Task利用率。
- Spark App集群资源时间占用CPU Core(Memory)*time。
- Driver 内存gc情况。
- Executor内存平均gc情况。
优化建议:
1)设置最小最大executor数量。
2)设置合理的Executot内存,spark.executor.memory。
3)设置合理的Executor Task并行度,spark.executor.cores。
4)通过聚合多个应用的资源时间占用,可以分析出Spark对集群逻辑资源占用的占比,为进一步管理员进一步优化打下基础。
实现(Implementation)
系统架构
-> spark application running
-> log event(e.g, taskStart, taskFailed, taskCompleted, executorAdded, executorRemoved…)
-> replay log and rebuild optimizated model
-> apply config rules on the model
-> make tag on this application, so user could search for this application and optimize according to the analysis result.
基于Dr-elephant,Spark诊断调优系统的工作流程: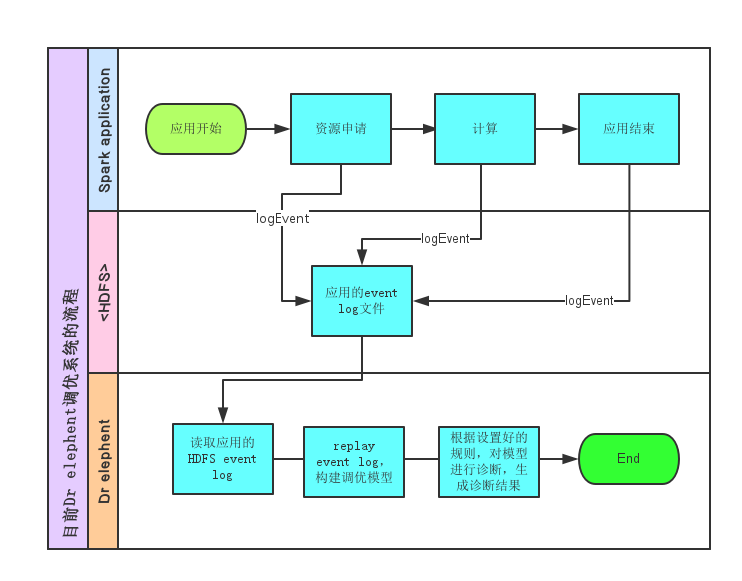
指标获取实现
应用Executor物理内存使用率。
这个指标是时间相关指标,各个Executor通过heartbeat向Driver传输并汇总。应用Executor CPU slot使用率。
表示Executor实际的CPU物理使用率。同上,各个Executor通过heartbeat向Driver传输并汇总。应用逻辑物理和内存资源占用。
通过YARN API获取到。表示应用占集群资源的逻辑资源量。使用Memory(CPU Cores) * seconds来表示。应用HDFS/Shuffle数据读写量。
通过YARN API获取到,表示应用的数据读写量,表示应用类型。- MapReduce:通过YARN API来获取。
- Spark:通过聚集每个Task的数据读写量来实现。
Hive SQL/Spark SQL语句保存。
一些Case总结
- 某个应用中,第一个Stage的某两个Task执行特别慢。
admin发现应用是卡在读取数据阶段。总是由某几个数据块,读取时间超长,本应该几秒读取完,实际花费几十分钟。结合代码和log发现,原因不在于Spark应用本身,而在于HDFS datanode响应速度极慢,所以需要进一步去检查为何datanode响应时间极慢。这样的应用到底有多少,需要通过系统来记录,并且反馈给admin。 - 应用的Job failed问题。
- 应用的资源占用率问题。