Hive Metastore保存了公司级别的核心元数据信息,所以其稳定性和高可用需求强烈。
如果Hive/Spark/客户端都使用直连MySQL访问方式,那么有诸多缺点:
- Metastore稳定性无法保证。
- 无法实现Hive审计日志。
- 无法实现Hive集中权限控制。
所以对于公司生产环境,强烈建议将Hive Metastore服务化,通过多台的Hive Metastore Server(以下简称MServer)来实现Metastore的高可用服务。
以下内容包含MServer性能测试、MServer内存调优、MServer参数调优和MServer运维与监控等内容。
1 MServer测试
1.1 测试环境
硬件配置: 24 CPU Core/64G memory/10GB bandwidth Network
1.1.1 MServer JVM启动参数:
|
|
1.1.2 MServer关键参数默认值
- 最大数据库连接池连接数200
- 处理线程数量最小200,最大2000
1.2 测试负载
模拟多个客户端,对MServer线性不同的进行请求操作。
请求操作有以下三种:
show tables: 查询一个库中的所有表操作,数据量少。show partitions by filter: 按照筛选条件查询一个表下的分区信息,在select表时候使用,具体逻辑由多条SQL组成,回发数据量较多。create table & drop table: 建表和删表操作,涉及到数据库读写操作,HDFS路径建立。getconf: 读取MServer配置,不与数据库进行交互,用来测试Thrift Server的最大处理能力。- 以上三种操作的混合,按照50%,40%,10%的比例进行混合。
1.3 测试指标
请求平均响应时间: 客户端请求的平均响应时间。QPS: 测试MServer的最大并发处理能力。
1.4 基本能力测试
目标是测试MServer最大处理能力,和在不同配置下的性能表现。
测试变动因素的有Server最大数据库连接数,测试操作,并发请求量。
1.4.1 不同并发请求量
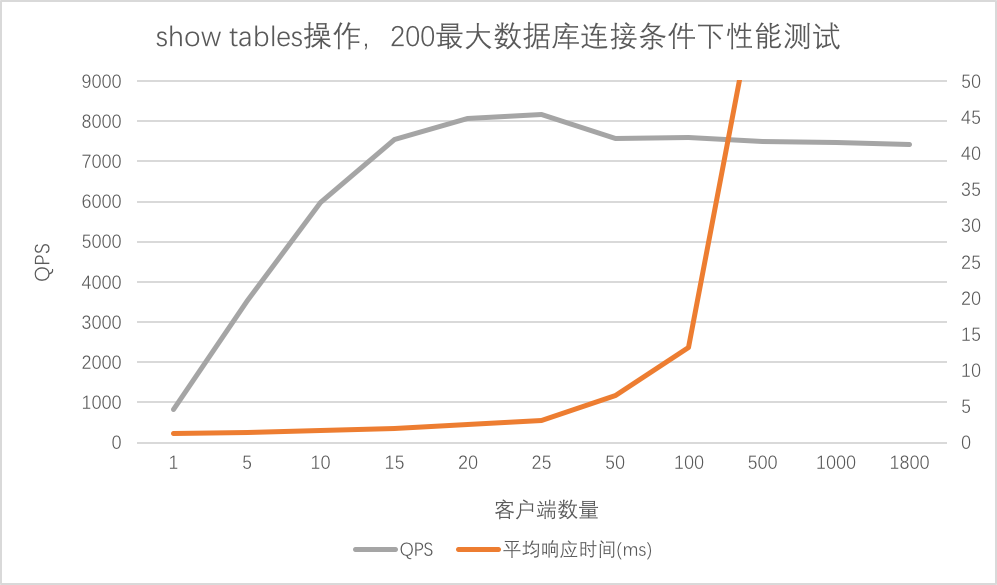
可以看大MServer在25个客户端并发下达到最大QPS达到8154,在100个客户端下平均请求响应时间13.17ms,之后上升较快。
注意: 这里的客户端不是普通的一个Hive客户端,因为其不间断的在对MServer进行请求。
1.4.2 不同MServer数据库最大连接数条件下的测试
- 最大数据库连接200
如前图结果所示。
- 最大数据库连接数400
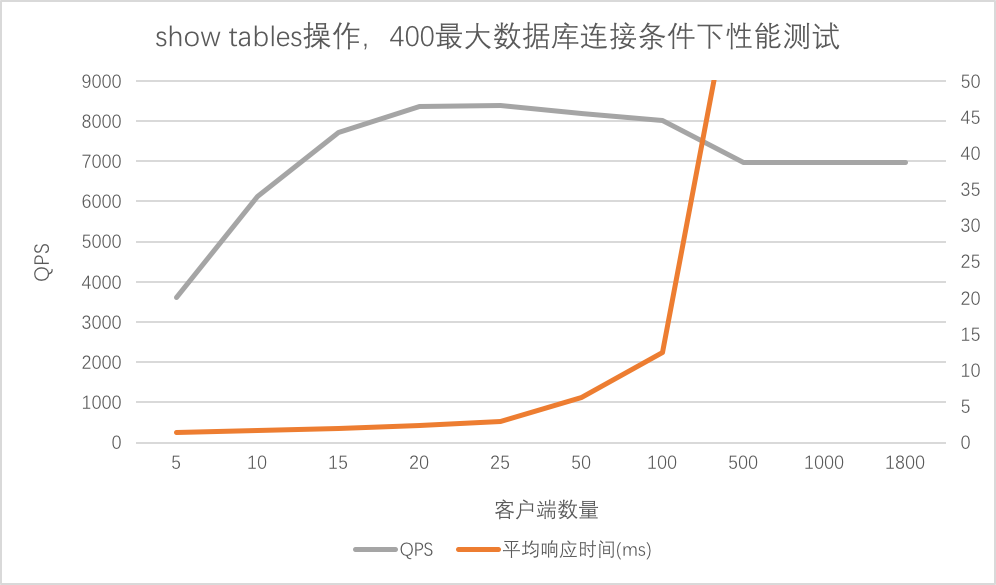
可以看大MServer最大QPS达到8395,在100个客户端下平均请求响应时间为12.48ms,之后上升较快。
- 最大数据库连接100
最大QPS在于7200左右。
与最大连接数200相比,增加到400对于QPS和平均响应时间的提升效果不明显,
所以分析响应瓶颈在于MServer操作的逻辑;或在于数据库的处理能力,虽然连接数增多,但是处理能力却不能得到提升。
1.4.3 不同请求操作类型条件下的测试
show tables
测试结果如前所述,最大QPS达到8395。
getConf
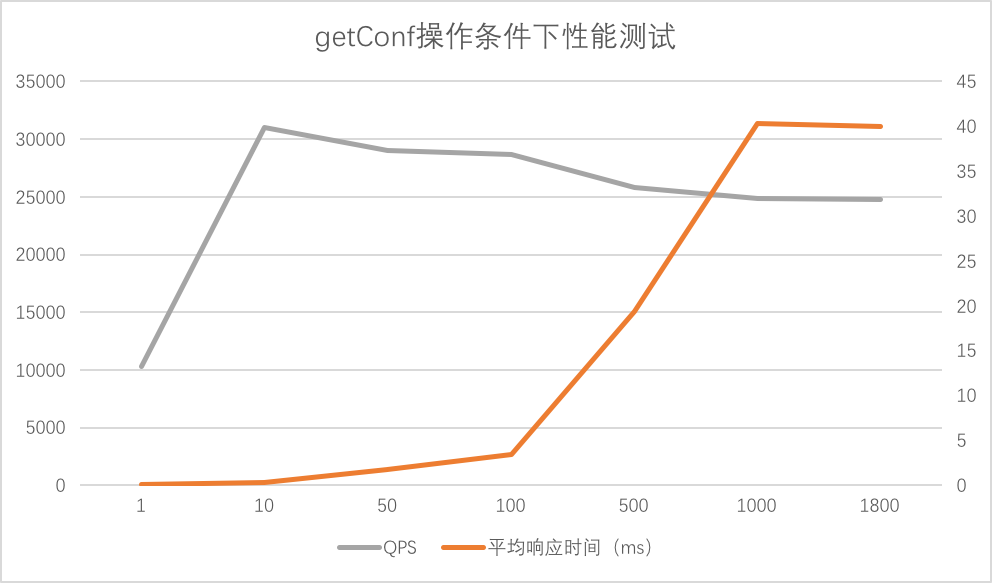
可以看到最大QPS达到31005,相比访问数据库的show tables操作的8395QPS,处理能力很大提升。
另外启动两个MServer实例,分别进行压力测试,两个MServer的QPS平均每个在4000左右,
通过上述线程认为数据库处理能力是制约MServer处理能力的主要因素,但是数据库连接数对增加数据库处理能力作用有限。
create table & Drop table
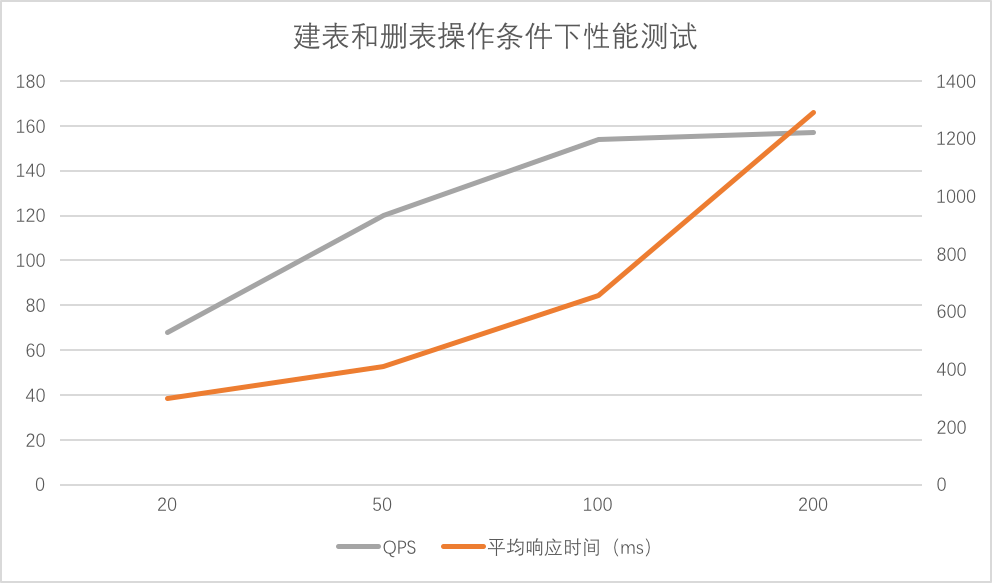
因为涉及到数据库写操作,和HDFS路径建立操作,平均QPS为157。
show partitions by filter
查询数据量较多时(255个partition),在测试时候会造成MySQL的System CPU使用率达到30%+。改变参数,降低获取的数据量后,System CPU使用会恢复正常。
这个现象还需要继续测试查找原因。
- 混合操作
最大QPS为416。
1.5 稳定性测试
连续压测20个小时,QPS能够保持稳定,CPU400%~600%左右,GC无异常,内存使用最大使用2g。
1.6 测试总结
- 数据库连接数对于性能的提升不明显,在MServer的处理能力提升不明显。MServer部署不需要特别多的数据库连接。
- 数据库处理能力是制约MServer处理能力的主要因素,但是数据库连接数对增加数据库处理能力作用有限
- MServer具有一定的稳定性。
- MServer在压测时候
CPU和Memory使用率都很低,Network使用也不多,不是资源高消耗应用,TCP连接数最大可以达到worker数量。
2 MServer部署
2.1 MServer启动参数设置
需要在${HIVE_HOME}\conf\hive-env.sh中增加:
|
|
这里GC使用常见的CMS+ParNew GC, 并且滚动打印GC log。
2.2 MServer的关键性能参数
hive.metastore.server.max.threads
Thrift Server工作线程的最大数量。默认是100000,但是一般设置为2000~4000。
如果并发瞬时请求大于这个配置,客户端会直接报连接错误,所以应该满足MServer instance * hive.metastore.server.max.threads > Max of Hive client at same timehive.metastore.server.min.threads
Thrift Server工作线程的最小数量,默认为20。MServer使用了Thrift Server中的ThreadPoolServer方式作为Server工作调度器。datanucleus.connectionPool.maxPoolSize
设置MServer的数据库连接池最大连接数。
MServer的一个很大作用也在于复用本来独立于各个Client的数据库连接, 大大降低了后端数据库的连接数。
每个MySQL Server实例的支持最大连接大概是4000,如果每个Hive客户端都去连接的时候,很容易打满连接,造成数据库too many connections错误
跟数据库的处理能力有关系,在测试中发现这个配置从200提高到400,MServer的处理能力并没有更多提升。
hive.hmshandler.retry.attemptshive.hmshandler.retry.interval
以上两个参数MServer在连接元数据库连接失败时候的重试次数和重试间隔。默认是10次,2s。当元数据库不稳定时候可以增加。
测试和观察MServer的log,发现在MServer在遇到HDFS读写异常(没有权限/Trash满等原因造成)时候,并不会重试,直接给客户端返回错误信息。li
当遇到JDOException和NucleusException等数据库连接错误时候,会进行重试机制。
hive.metastore.server.max.message.size
MServer与客户端传输消息的最大值。默认是200MB,一般够用,如果遇到奇葩错误,可以调大。
2.3 客户端相关参数
hive.metastore.local
使用远程MServer设置为false。
hive.metastore.uris
设置为MServer地址,多个MServer实例使用逗号分隔,注意地址一定要符合URI的RFC规范,是thrift://hostname:port这样的形式。
hiv.metastore.connect.retries
客户端在连接MServer失败时候的重试次数,默认为3。hive.metastore.client.connect.retry.delay
客户端在重试连接MServer时候的重试间隔,默认为1s。建议设置为5s~25s,我们集群设置为6s。
以上两个参数是Hive客户端在启动尝试连接MServer时候的相关参数。
另外一个比较重要的参数是查询过程中MServer出错,自动尝试到另一个MServer上去查询的参数:
hive.metastore.failure.retries
客户端在连接MServer进行查询时候出错的重试次数,默认为1。
上述三个是客户端连接MServer的高可用相关参数。
查询失败的原因可以总结为:
MServer实例重启,这个在MServer配置变更和服务升级时候会发生。
MServer实例异常。主要为无响应,或者依赖的元数据库响应异常。
当依赖的元数据库异常时候,MServer如上面所述会采取重试机制,而此时客户端并不会重试,会hang住等MServer进行重试返回结果。
客户端请求异常。
目前经过分析MServer的运行log,只发现一个case,
是在删除内部表操作时候,删除用户目录外的HDFS数据到用户目录下Trash如果权限不足(用户根本没有申请到用户目录权限),
或者用户目录配额满的时候会引发MServer删除表异常。通过构造这种场景测试测试和代码验证,发现客户端并不会重试。
上述三种情况,只有当第一种原因发生(客户端异常为传输异常(TApplication|TProtocol|TTransport等))时,客户端会采取重连措施。
综上所述,为了防止第一种情况的发生,增加连接MServer时候的高可用特性,建议增加重试次数。
参考IBM Enabling Hive metastore high availability
中的配置,并结合集群情况,将重试次数设置为25,重试间隔设置为6s,这样将会允许客户端有150s的重连缓冲时间。
MServer作为一个高可用服务,如果150s内不能恢复服务,那么客户端直接报错。
hive.metastore.client.socket.lifetime
客户端在进行某一个查询,超过多长时间就会进行选择另一个MServer重试。默认为0s,配置文件一般设置为600s。
2.4 Hive auditlog配置参数
通过metastore回收元数据访问权限,顺便可以打开Hive的元数据audit log功能,进一步可以做一些Hive表冷热分析,HDFS数据访问频率分析等额外工作。
打开Audit log并输出到单独文件,需要修改的是${HIVE_HOME}\conf\hive-log4j.properties文件:
Hive 1.2.1参数log4j.properties
Hive 2.1.1版本log4j2.properties
3. Metastore运维与监控
3.1 外部监控系统
可以使用Ganglia和Zabbix等监控系统。
3.2 监控指标
3.2.1 节点监控指标
包含一些机器常用指标,包含CPU/Memory/DiskIO/NetworkIO等。测试过程中发现MServer的负载很低,需要关注的主要是NetworkIO和TCP connection两个指标。
3.2.2 进程监控指标
监控进程是否存在。
3.2.3 MServer负载监控指标
设每个MServer的工作线程最大为MaxWorker,每个客户端与Server连接之后会使用一个TCP连接,
可以用Server的TCP连接来作为表征Server负载的指标。
可以设置每台机器的Server TCP连接数大于门限(例如90%)则进行告警。然后触发扩容等措施。
3.2.4 应用级别监控指标
引入社区的Hive Metrics机制。另外可以模拟一个业务监控,定期进行一次查询以检测可用性。
例如定期执行这样的命令:hive --hiveconf hive.metastore.connect.retries=1 --hiveconf hive.metastore.failure.retries=1 --hiveconf hive.metastore.uris=thrift://127.0.0.1:9083 -e "show databases;" > /dev/null 2&>1
4 待补充工作
- MServer Metrics收集,监控和告警。
- MySQL System CPU使用率在压力测试请求频繁条件下超高问题。
- 通过Metrics收集真实的请求量分布,便于在运维时候提前增加Server数量,应对请求高峰。
- MServer Cache机制。